Kafka
一、软件介绍
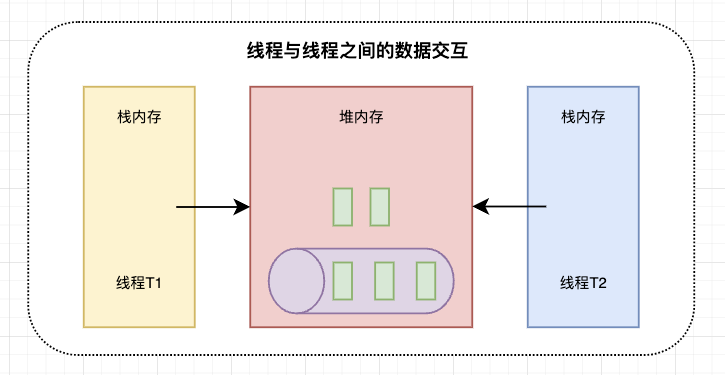
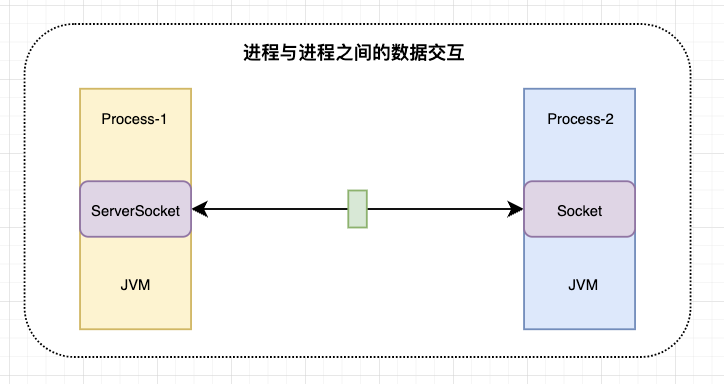
存在的问题
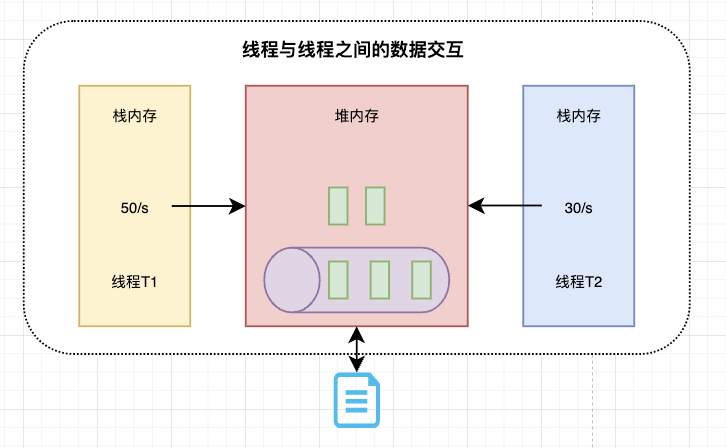
当一个线程50/s写入,一个线程30/s消费,那么随着时间的累积会造成大量内存消耗,如果把这部分数据写入磁盘中,长期看来,也会造成大量资源消耗浪费,甚至系统不可用
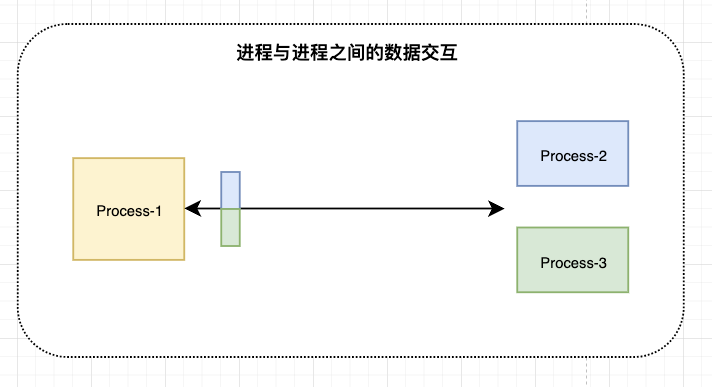
当一个进程需要向多个进程发送数据时,需要发送两份,造成资源浪费,如果数据不同,且指定对象,要增加逻辑和不同标记作为区分,增加进程复杂度,消耗资源,降低系统的反应速度,重复发送也会对系统吞吐量造成影响
解决方法
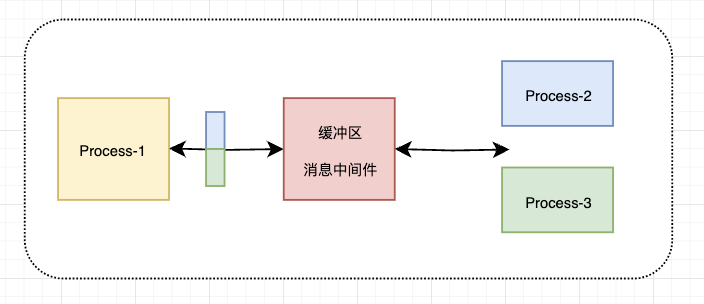
进程之间不直接通讯,增加缓冲区,降低进程之间的耦合性,对数据生产和接收进行调整,使传输过程平稳高效
接收方也可以根据自己的业务场景动态的从缓冲区中获取自己想要的数据,发送方只考虑向缓冲区中发送数据就可以了
缓冲区:对数据进行中转和临时存储,并不会对数据进行处理,所以这个第三方软件也被叫做消息中间件
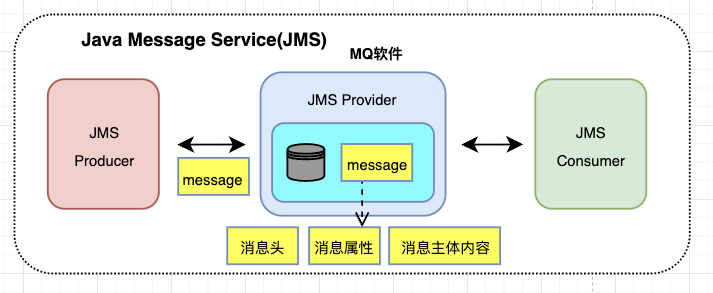
二、JMS
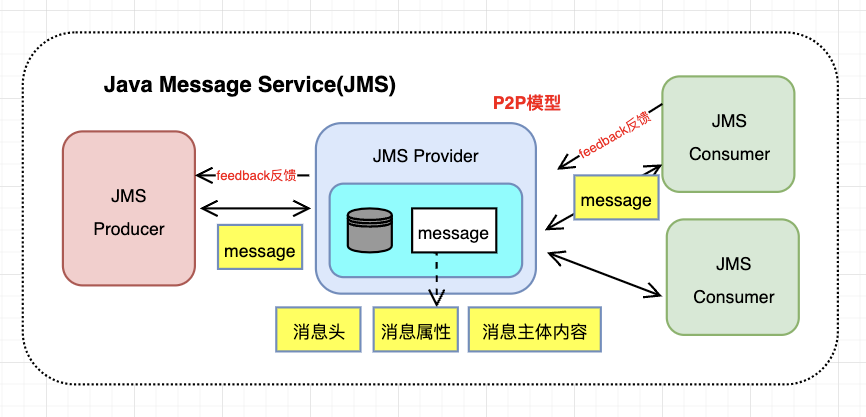
P2P模型
点对点 point-to-point
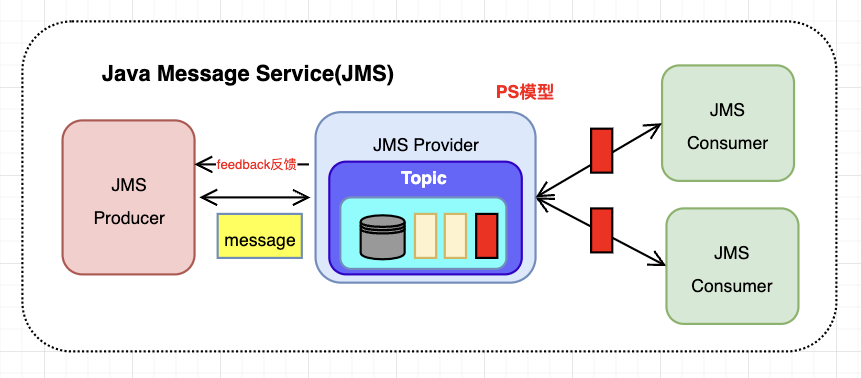
PS模型
同组的人只能有一个人消费,不同组的人可以消费
RabbitMQ、ActiveMQ、RocketMQ、Kafka
消息中间件对比
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比RocketMQ、Kafka低一个数量级 | 万级,比RocketMQ、Kafka低一个数量级 | 10万级,支持高吞吐 | 10万级,支持高吞吐 |
| Topic数量对吞吐量的影响 | Topic可以达到几百/几千量级 | Topic可以达到几百量级,如果更多的话,吞吐量会大幅度下降 | ||
| 时效性 | ms级 | 微妙级别,延迟最低 | ms级 | ms级 |
| 可用性 | 高、基于主从架构实现高可用 | 高,基于主从架构实现高可用 | 非常高,分布式架构 | 非常高,分布式架构 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化,可以做到0丢失 | 经过参数优化,可以做到0丢失 |
| 功能支持 | MQ领域的功能极其完备 | 并发能力强,性能极好,延时很低 | MQ功能较为完善,分布式,扩展性好 | 功能较为简单,支持简单的MQ功能,在大数据领域被广泛使用 |
| 其他 | 很早的软件,社区不是很活跃 | 开源,稳定,社区活跃度高 | 阿里开发,社区活跃度不高 | 开源,高吞吐量,社区活跃度极高 |
三、Kafka组件
